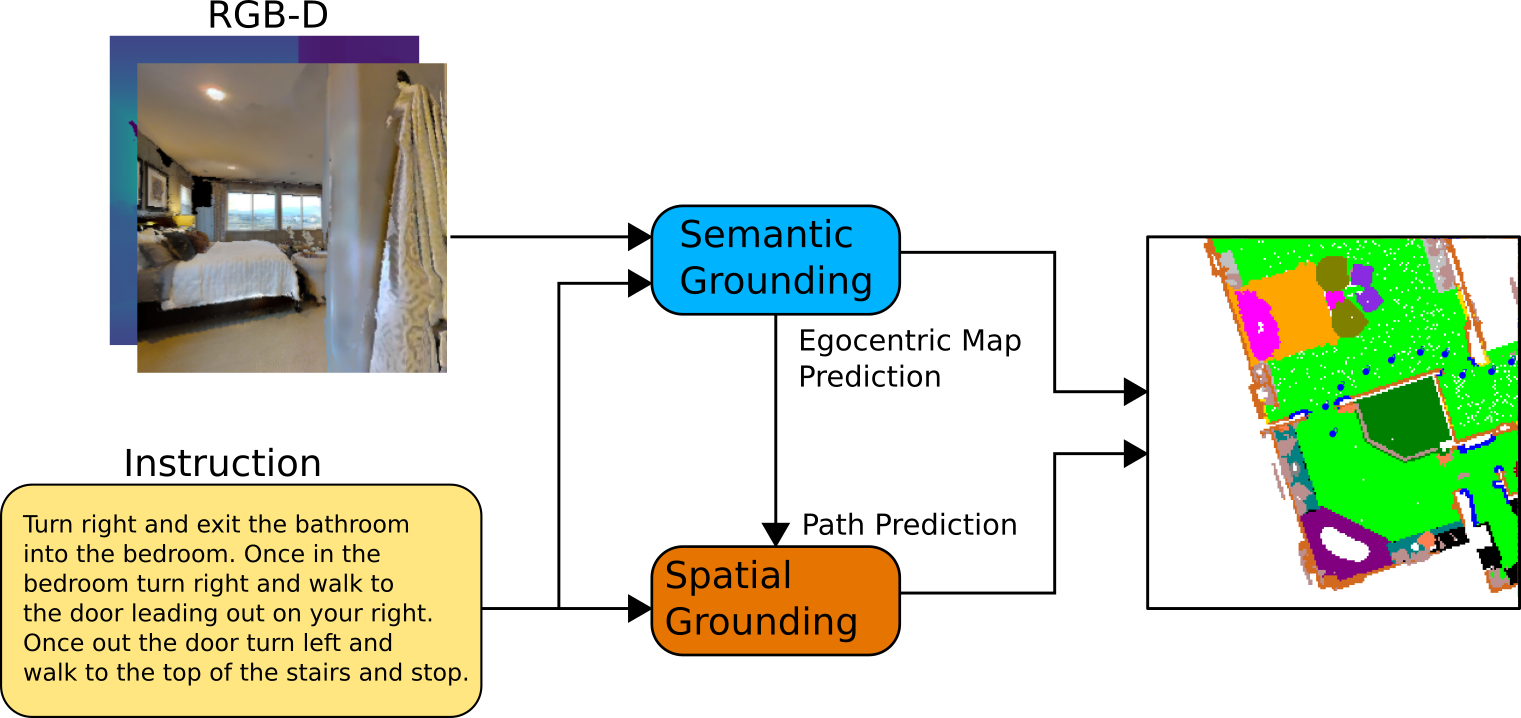
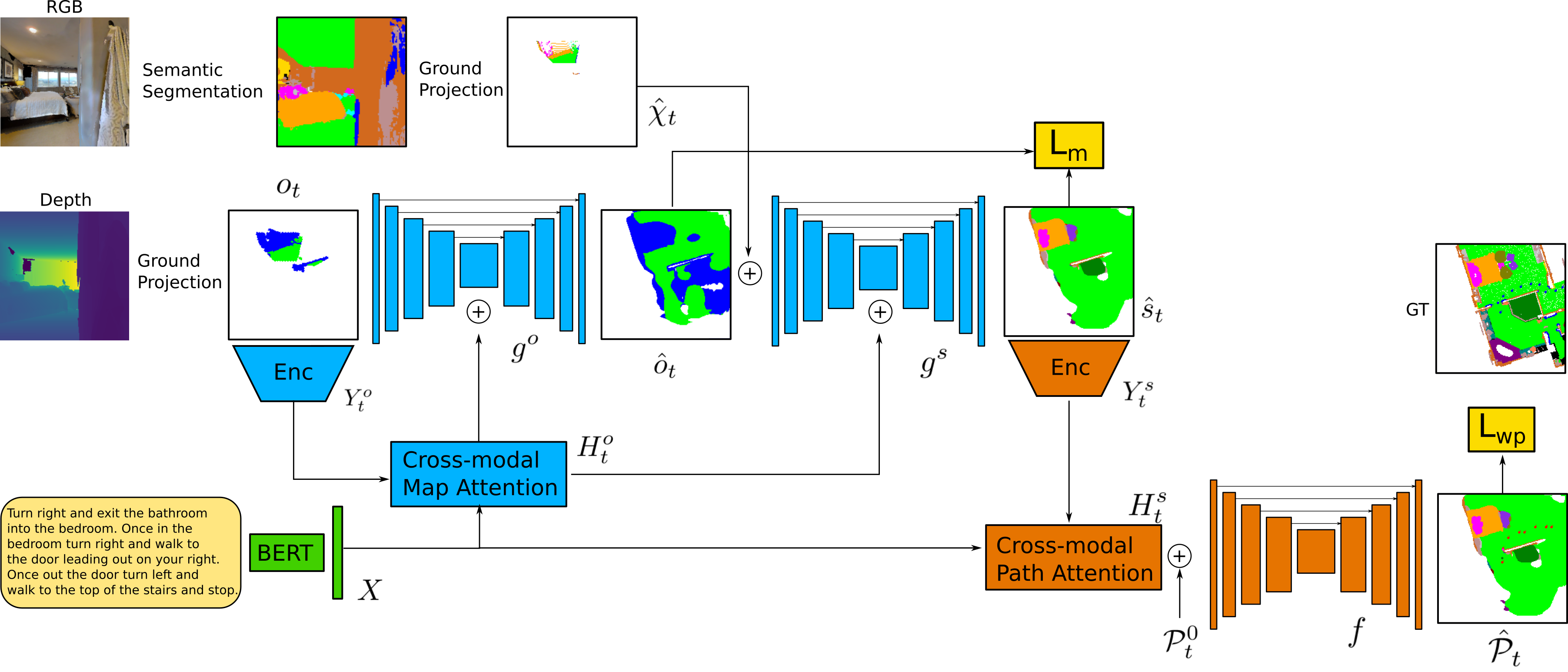
Cross-modal Map Learning for Vision and Language Navigation
CVPR 2022
Georgios Georgakis
Karl Schmeckpeper
Karan Wanchoo
Soham Dan
Eleni Miltsakaki Dan Roth Kostas Daniilidis
Eleni Miltsakaki Dan Roth Kostas Daniilidis