Overview
Operating in novel indoor scenes presents several challenges. First, unstructured environments are visually complex; the agent needs to recognize multiple object categories from different viewpoints and under occlusions in addition to parsing the structure of the scene to floor, side walls, and doors. Second, the agent needs to consider the spatial complexity of unseen environments, in other words, the set of expected semantic configurations. We aim to address these issues by learning how to predict semantic maps. Through this task a model can learn spatial associations between semantic entities and use this information to reason beyond the field-of-view of the agent. Particularly, in this research thrust we hypothesize that learning semantic layout patterns of indoor scenes increases the robustness of navigation agents towards the visual and layout complexity of previously unseen environments. We propose the following: 1) a novel framework for hallucinating occupancy and semantic regions beyond the field-of-view of the agent, 2) methodology for quantifying model uncertainty of the inferred information over unobserved areas, 3) an active training procedure for the semantic map predictor, and 4) objectives for multiple navigation tasks based on the map prediction and uncertainty.
Papers

Learning to Map for Active Semantic Goal Navigation, ICLR 2022
We consider the problem of object goal navigation in unseen environments. Solving this problem requires learning of contextual semantic priors, a challenging endeavour given the spatial and semantic variability of indoor environments. Current methods learn to implicitly encode these priors through goal-oriented navigation policy functions operating on spatial representations that are limited to the agent's observable areas. In this work, we propose a novel framework that actively learns to generate semantic maps outside the field of view of the agent and leverages the uncertainty over the semantic classes in the unobserved areas to decide on long term goals. We demonstrate that through this spatial prediction strategy, we are able to learn semantic priors in scenes that can be leveraged in unknown environments. Additionally, we show how different objectives can be defined by balancing exploration with exploitation during searching for semantic targets. Our method is validated in the visually realistic environments of the Matterport3D dataset and show improved results on object goal navigation over competitive baselines.

Uncertainty-driven Planner for Exploration and Navigation, ICRA 2022
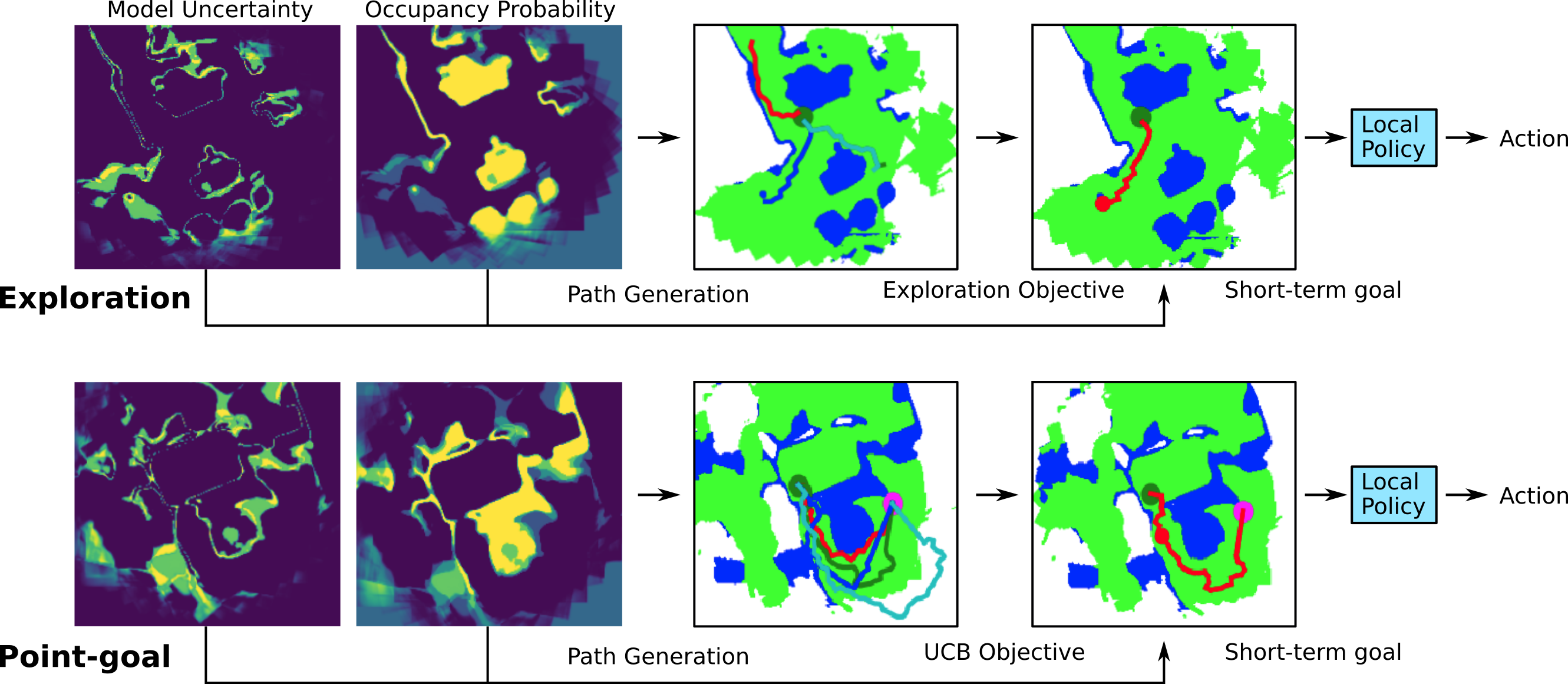
We consider the problems of exploration and point-goal navigation in previously unseen environments, where the spatial complexity of indoor scenes and partial observability constitute these tasks challenging. We argue that learning occupancy priors over indoor maps provides significant advantages towards addressing these problems. To this end, we present a novel planning framework that first learns to generate occupancy maps beyond the field-of-view of the agent, and second leverages the model uncertainty over the generated areas to formulate path selection policies for each task of interest. For point-goal navigation the policy chooses paths with an upper confidence bound policy for efficient and traversable paths, while for exploration the policy maximizes model uncertainty over candidate paths. We perform experiments in the visually realistic environments of Matterport3D using the Habitat simulator and demonstrate: 1) Improved results on exploration and map quality metrics over competitive methods, and 2) The effectiveness of our planning module when paired with the state-of-the-art DD-PPO method for the point-goal navigation task.
Architecture
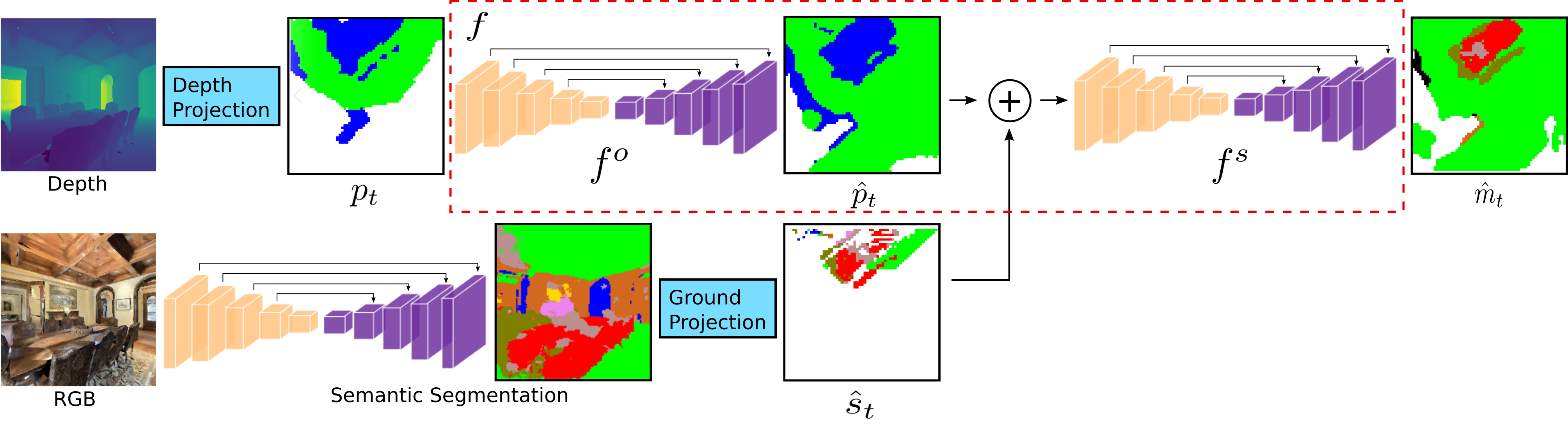
Active Training

Planners for exploration and point-goal navigation tasks
Object-goal examples
Exploration and point-goal examples
Acknowledgements
We would like to thank Samuel Xu for implementation support in evaluating baseline methods. Research was sponsored by the Honda Research Institute through the Curious Minded Machines project, by the Army Research Office under Grant Number W911NF-20-1-0080 and by the National Science Foundation under grants NSF CPS 2038873, NSF IIS 1703319, and NSF MRI 1626008. Further support was provided by the following grants: NSF TRIPODS 1934960, ARL DCIST CRA W911NF-17-2-0181, ONR N00014-17-1-2093, the DARPA-SRC C-BRIC, CAREER award ECCS-2045834, and a Google Research Scholar award. The views and conclusions contained in this document are those of the authors and should not be interpreted as representing the official policies, either expressed or implied, of the Army Research Office or the U.S. Government. The U.S. Government is authorized to reproduce and distribute reprints for Government purposes notwithstanding any copyright notation herein.
The design of this project page was based on this website.